万万想不到啊,MIT数学考试,被GPT-4攻破了?!
突然有人在最新论文工作中高调宣布:
GPT-4在MIT的数学和EECS(电气工程和计算机科学系)本科学位考试中,表现出的能力完全满足毕业要求。
而且妥妥地拿下满分!

要知道,测出这个结果的不是别人,正是来自MIT和波士顿大学、康奈尔大学的研究团队。
而且强如上一代王者GPT-3.5,在同样的测试中,只成功搞定了三分之一。
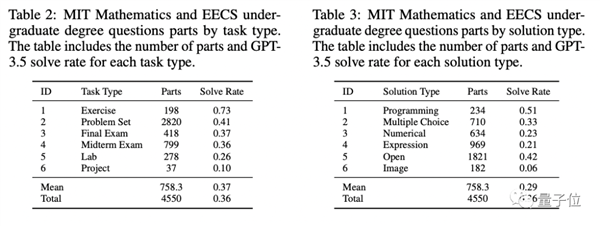
△GPT-3.5考试成绩
论文一出,无数目光迅速被吸引过来。
GPT-4这样看似开挂的行为,自然引发了不少网友的感慨。
比GPT-3.5强好多,好耶!
咱就是说,有没有可能以后不需要比GPT-4更强的模型,来解决学术问题了?
还有网友展现了自己网上冲浪的“前沿性”,玩了个这两天Yann LeCun吐槽“GPT-4智商不如狗”的梗:
GPT-4开挂MIT考试
具体来说,GPT-4这次是参与了这样一场测试:
研究团队策划了一个数据集,其中包含4550个问题和解决方案。
这4550个问题和解决方案,来自MIT数学系和EECS的学生获得本科学位,需要学习的课程问题集、期中考试和期末考试。
包括:
6-1:电气科学与工程;6-2:电气工程与计算机科学;6-3:计算机科学与工程;6-4:人工智能与决策;18-1:普通数学;18-2:应用数学;18-3:纯数学;18-C:数学与计算机科学。
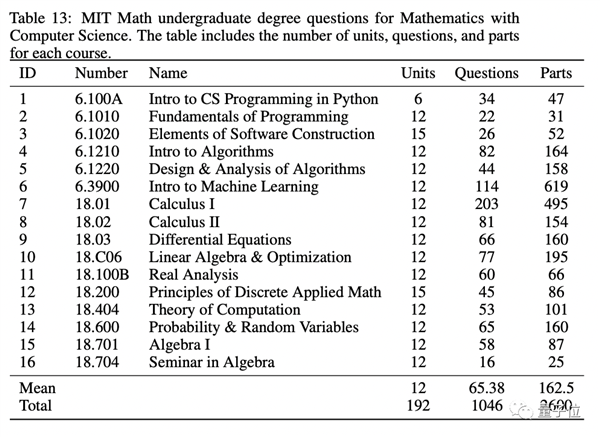
△每个专业的详细分类总结
题目统统出自MIT的数据集,从中随机生成228个问题,不涉及图像和已有解决方案的问题。
题目的难度等级由易到难依次为:练习、习题、 期中考试、期末考试、实验和专题。
按答案类型排序,题目的难度由易到难依次为:编程、开放、选择题、数值、表达式和图像。
这一次,参与考试的不只有GPT-4和GPT-3.5,还有StableVicuna-13B、LLaMA-30B和LLaMA-60B。
选择让这4个大模型作为考试参赛选手,原因是它们是“最先进的大语言模型”。
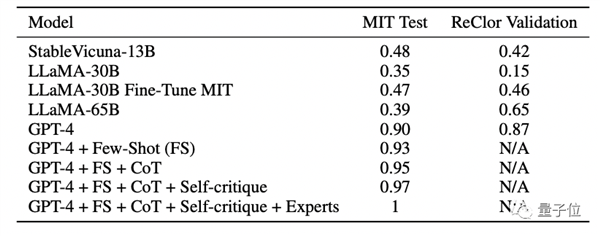
△最终考试成绩
通过表格里的数据可以看到,得分最高的是经过调优后的GPT-4,得分率100%;表现最一般的是LLaMA-30B,只拿下了30%的分数。
值得关注的是,原始版本的GPT-4开箱即用,完全不经过调优,在本次MIT考试中也拿到了90%的分数。
调优流程,包括Few-Shot+CoT+Self-critique+Experts。

从最终考试成绩的表格数据可以看到,从左到右每增加一个环节,调优后的GPT-4得分都会更上一层楼。
此外,研究团队还在提示框里进行了工程优化,具体的“咒语”如下:

等等,评分人是GPT-4自己?
看到这样的结果,不少网友心生感慨,LLM在数学考试上的进步,未免有些神速了哈。
2年前,AI还在苦苦挣扎小学数学问题。
类似“小明种了5棵柠檬树,每年从每棵树上得到6个柠檬,10年间他总共得到多少柠檬”这种。

去年年初,MIT+哈佛+哥伦比亚大学+滑铁卢大学的联合研究表示,把数学问题转换成等价的编程问题,就可以让GPT-3的同门师兄弟——OpenAI的Codex掌握高数,达到MIT本科水平。
学了6门MIT本科基础数学课里随机抽取的例题,6门课程每门随机出25道题,再加上一个ACT水平(美国高考)的数据集里的60道题。
总计210道题,AI全部答对。

不过有人提出,AI达到的“MIT本科水平”,实际是Codex在做语言题而非数学题——
因为当时的评测中,Codex负责读写,并不包括求解。
所以,这一回GPT-4表现奇佳,怎一个妙字了得~

好了,知道你很着急夸它,但你先别着急夸它,因为很快有人发现了一些“诡异”。
主要有2大槽点。
第一个值得质疑一番的,就是OpenAI的训练数据集没有完全公布。
这也就意味着,无法证明数据集中的4550个问题和解决方案,在GPT-4的训练集中不存在。
换句话说,如果GPT-4在预训练阶段已经接触到了这次的考题们,那最终拿下完美得分,就没什么好惊喜的了。
也难怪乎有网友毫不客气地yygq,认定GPT-4拿到这样的结果,一定是数据集已经包含在训练数据里了。
第二个槽点,就是GPT-4最后100%的得分率,似乎哪里不对劲???
定睛一看,在论文的第2.6节有一句很关键的点:
团队在数据集上微调开源大模型,“给定问题Q、基本事实解S和LLM答案A,我们使用GPT-4自动对模型响应进行评分”。
实际操作上,就是每个大模型生成这次考试的答案,然后派出GPT-4打分,分值在0-5之间。
所以给GPT-4打出满分的,实际上是GPT-4自己。
啊这……很难说没有王婆卖瓜自卖自夸的嫌疑。

此外,关于要给GPT-4提供“好的提示”,才能让它达到满分成绩,也让许多人抱有微词。
到底什么算“好的提示”呢?似乎无法定义。
甚至有人喊着,应该把这些题丢给MIT数学和EECS的学生去做,并不断给他们“好的提示”,这样人类学生也能拿下100%的吧……
One More Thing
一个小小的彩蛋:
整个测试中,基本上可以在笔记本电脑上部署运行的StableVicuna-13B,也有48%的得分率。
这个成绩,不仅比模型更大的LLaMA-65B高出近10个百分点,就连MIT fine-tuing过后的LLaMA-30B,还要高。
让人不得不陷入一些关于模型规模与能力相关性的思考。
参考链接:[1]https://arxiv.org/abs/2306.08997
[2]
[3]
[4]
来源:量子位